
Software ain’t what it used to be
I am assuming that you are somewhere in the management hierarchy of a large organisation. I am also assuming that the organisation either does not use Agile yet, or has adopted Agile for teams that are developing software and finds things are not yet smoothly integrated into a total ‘Agile organisation’. Typically, the interface between development, planning, project management and progress tracking are areas of friction.
I am also assuming that you are not highly ‘technical’ - why would you be if it is not part of your job? Software developers, like any group of professionals, have their own language for discussing the things that matter to them, and people outside that group do not need to know all the details. There is no deliberate attempt to confuse issues here – it is just that each field develops its own specialist language.
Having said that, there is an important relationship between what a software project is and the way it is managed. The nature of software projects and software development has changed drastically over the years and many of the older management strategies are no longer relevant. Agile embraces many of these changes and has totally changed the way software is developed to support these changes. Agile also supports better ways of managing the delivery of software, but this is rarely explained and supported at an appropriate level.
1. What is a piece of software?
The origins of systematic software development and management of software development can be traced back to the early 1950’s. The whole nature of computers, programs, programmers and users was different then. Basically, you had a program and a set of data. You ran the program and it processed the data, producing a new set of data. That was it. Programs were written by a small number of programming gurus for a specific machine and they basically spent their lives looking after that machine and software forever. Computers were expensive, people were cheap – so getting people to adapt to the computer was a better solution than making the computer adapt to people. It is hard to understand how different things were. Try this. Thomas J Watson, the head on IBM (who were leaders in commercial computing back then) said (in 1943) “I think there is a world market for 5 computers”. Understandable. Computers were the size of a house, were hugely unreliable, ate as much electricity as a small town and people thought that only governments could afford them. Who could predict that 50 years later they would be smaller than a fingernail and we would all be carrying them around in our pockets? That has changed everything about computers – including what we commonly mean by software.
As the nature of software has changed, so have the development processes – but the techniques for managing software development have not always kept up. Here are some key changes in software development:
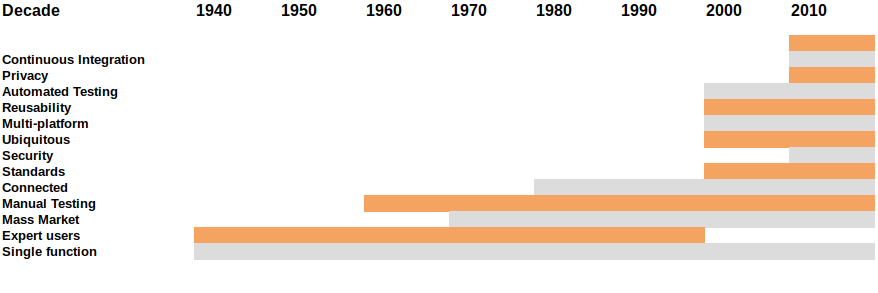
The dates are approximate, but the overall view demonstrates the point
- Single function – You have a program and some data. You run the program and it makes some new data
- Interaction with expert users - Highly trained people can interact with the software while it is running to change what it does
- Mass market computers and non-expert users – As computers become cheaper, people with less training and expertise are allowed to use them. We have to start designing software to make it easier to use and prevent mistakes. This is the beginning of the 'User Interface' and introduces a new level of requirements to the software we write
- Manual testing - Amazingly, most early software was not tested. A programmer wrote it and it was assumed that it was correct. This resulted in some very expensive mistakes. The first ways to rectify involved writing 'test cases' which a human could follow to make sure the software worked as intended
- Connected computers – Internet and web. Computers were originally individual machines which did things. Starting in the 1960's (from military origins) it was recognised that connecting machines together was important. They could exchange information, share work and were more reliable. Connected by telephone lines, the Internet was developed as a way of exchanging information between machines in a robust manner (so even if lines are destroyed it will find other ways). The internet originates in the 1960's. The web is one way to use the Internet which is more suitable to humans. It started in the 1990's and is now the main means of distance interaction for humans and computers
- Standards - There was a time when each computer manufacturer made their own hardware and software for their own systems and if you bought a machine you were also committing to buying software for that machine for the rest of your life. The introduction of standards (which took a long time to become common) meant that you could choose hardware and software from different sources and it would still work
- Security - once you start connecting computers together, the security of your data becomes important. One computer might be in a very safe and secure place, but the minute you share information with another computer your security depends on how safe and secure that computer is and also on how safe and secure the connection you use to transfer information is. This is a continuously growing problem
- Ubiquitous devices – especially mobiles. A computer stops being a box with a screen, keyboard and mouse. It might be a phone, a games machine, a TV or a fridge, light bulb, car or doorbell (thinking ahead). So now you have to design versions of your software for all these different devices and the different ways they might be used
- Multi-platforming - this follows on from ubiquituous devices and standards. It makes no sense to design many versions of the same thing, so adopting standards which work across many platforms is the only way to go
- Reusability (and open source) - it is hard to explain how significant this has been. From a closed world where we write code and keep it secret, we now share as much as possible (under different licences) so there is no need to write new code if you can find an acceptable solution which has already been written by someone else. It changes what being a developer means
- Automated testing - Agile is fast and responsive, but not reckless. In many ways we set higher standards of approval and testing. The big difference is that these things are not 'added on' at the end of the project. We write code to test our code as we go along, so every time a new deployment happens all the code is tested again. This helps us meet the Standards of the modern environment, but it has the implication that a development process might easily require twice as much code as it did before
- Privacy - with connectivity and sharing of data comes much more responsibility. It is actually not a huge amount of extra work as long as you think about it and plan it from the start of a project. Adding it afterwards is more difficult. This involves collecting only the data you need, keeping it only as long as it is needed and protecting (encrypting) it while it is stored on your systems or communicated to other systems
- Continuous development and deployment - building a complete 'solution' and then deploying it is fraught with difficulty. Instead of staging things in sequence with big changes, it is much safer to do frequent, small changes. That is not always possible, but doing this to the greatest extent we can minimises risk and improves our responsiveness to users
Many of the techniques we use to manage software projects are basically unchanged since the 1960’s (about step 3 in the list). Agile comes in seriously round about step 9 (late 1990’s) though a lot of the techniques came earlier but did not have a group name.
A simple way of looking at this is where the effort goes in some code. Let’s separate: ‘the engine’; User Interface; testing; connectivity; security; privacy; multi-platform; deployment
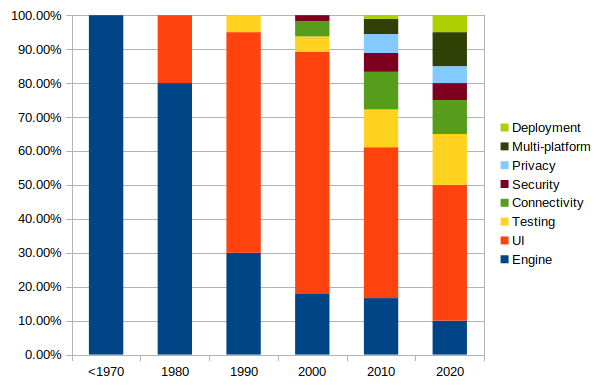
This is where the code effort goes. I am not claiming this graph is statistically accurate, but it shows the trend. It is also important to note that this reflects the balance between different aspects of the code, not the overall effort. Writing a commercially acceptable piece of software takes a lot more effort than it used to because we expect much more from it. The work involved in the 'engine' has not changed much. Better tools and better reuse of code has improved things but we are still expecting software to do much more than the engine. If we looked at the effort to produce a piece of code accounting for all factors, it has increased something like this:
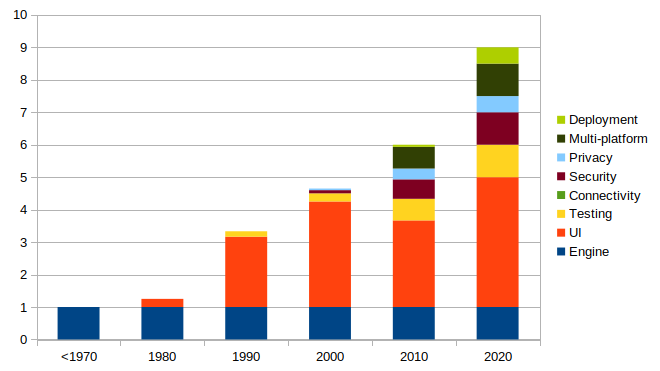
You will notice that the amount of effort which goes into producing code is far more than it was back in the 1970's. That is not because we are getting worse at it. These days we expect a lot more from a software solution than we did back then. Easy to use, error-free, secure, efficient, protecting data, self-testing, easy to maintain and working across many devices are just a few of the expectations we have introduced in the intervening period.
In both these diagrams, the different categories of work can be described as follows:
- The Engine - Originally, this was pretty much equivalent to ‘the software’. It does some stuff. It gets built to do one thing on one computer in an isolated room. No ‘users’ are allowed near it so no nice interface is required. Amazingly, by today’s standards, there is no concept of testing. No-one cares about reusability, security or deployment since it is only on one machine
- Testing really started in the 1960’s – a lot of it inspired by mistakes in the American Space programme which were very expensive (e.g. writing a semi-colon instead of a colon could destroy a rocket costing many million dollars). But testing was manual for many years - writing hand-coded scripts for humans to try against software and see what happened. It is amazing that many organisations still use manual testing. These days the expectation is/should be that the programmers (and others) write automated tests so all relevant aspects of any piece of software are tested before every deployment. (See discussion of testing below)
- The User Interface – once programs start becoming interactive, you have to let users do things with them. This means people who are not expert in that particular piece of software and how to deal with its oddness must be supported. Suddenly a lot of effort has to go into accepting interaction, validating it, testing it and dealing with problematic input from users. At the start of the 1970’s almost all effort went into the ‘engine’. By the end of the 1970’s the engine was only 10% of the effort – the other 90% was all about user interfaces. This was partly because we started using graphical interfaces with things like mice and menus. That uses a lot design time and a lot of computer time. It also makes a fundamental shift in software design to puts the user at the centre of what we do. Things like HCI (Human Computer Interaction) and UX (User Experience) all originate from this
- Standards/Reusability – this is a hugely important change in the way we work. Proprietary systems used to be how it is. A manufacturer would create their own hardware, with their own operating system and try to tie people into them that way. Hard to believe now, but IBM dominated the market for decades. In the UK there were over 500 operating systems for a while. After PCs started there were a lot of changes and consolidation happened. Users started expecting similar things on different platforms. A significant change was the introduction of ‘Open Source’ – people who write code and share it with the world – under different licences but basically for free. This helped us to share code so we get away from proprietary systems and do not keep writing the same thing again and again. This has also been helped by object-orientated approaches which help us write code in ways which are reusable
- Connectivity – connecting a computer to another computer is a really good thing. They can exchange information and ask each other to do work for them. But it also a really bad thing. There is the potential for them to corrupt data on other machines, be vulnerable to attacks to break the machine to steal data and more. Computers are basically connected over phone lines. The first such network was built for military purposes across military phone lines. Nowadays the internet lets any computer in the world connect to any other computer. Then the world-wide web (which is a layer over the internet) makes it even easier to do for any humans. That has implications for security and privacy which are world-wide. We need to design all out software to support this connectivity but also to keep us safe
- Multi-platforming – A computer is not what it was. It might be a big machine, or a desktop, or a laptop, or your TV, or your phone, or your games machine, or your smart watch, or your alarm clock, or your fridge. These are all computers. So now we have to make our software work not only on one machine, or a set of related machines but on drastically different platforms. On the good side, most of them work within standards. On the bad side, very few are 100% compliant with the standards. So now you have to design and test on many more systems than you ever did before
In summary, a modern computer program will typically consist of:
- An engine that does some important stuff
- A user interface that enables people to interact with it in an easy-to-use, secure and private manner
- A flexible user interface and architecture to work across different platforms and devices
- A set of communication interfaces to enable it to interchange data and request actions with other computers and devices
- A set of automated tests which are executed at every deployment to ensure integrity of the system
- An automated deployment mechanism supporting continuous development and improvement, stability of systems and automated handling of issues and other outages
- A set of monitoring tools which will show system performance and alert relevant people if any issues arise
- Structures that are easily maintainable and improvable by any skilled team – not just the team who wrote it
That is a long way from writing a program on one machine which reads some data, writes some output and ends. The idea of a ‘software solution’ has moved a long way and we need to change our expectations as an organisation to embrace this.
2. What does that mean for Project Management?
There are some exceptions to the things listed below, but in general they apply.
- You cannot take a definition of a program which ‘does something’, make it do that thing and call it done. Once we move past the simplest programs there is interaction (with humans and other computers) and many more issues come into play – far more that you could ever anticipate in advance. So the idea of “Requirements capture” as a complete process done before development starts is just fantasy. That means that planning a complete project in detail is a non-starter
- For similar reasons, the idea of a complete ‘specification’ written at the start of the project is not feasible. To clarify. Defining every aspect in every detail is neither possible, nor productive. Of course, we have to have an overall definition of the project and a clear view of what it will mean to have achieved our objectives. That does not mean that we can define every detail in advance. We learn and change as the project progresses. That does not mean that specifications are useless - but they are not fixed in stone. It is much more effective to specify just enough, just-in-time so it is always up to date with current knowledge and experience on the project so far. Try thinking about a series of 'micro-specifications' created just when they are needed
- User and stake-holder engagement is essential throughout a project - not just at the start and end
- A piece of software that appears to do what you want is not a solution. Maintainability, correctness, continuous improvement, automated testing, deployment and monitoring are all part of a solution
3. How does that relate to Agile?
Agile approaches are based on empirical data and reality. If something is desired in a project then there must be good, justified reasons for it. Just saying 'I think this is a good idea' is not enough. The view of software described above has helped us develop Agile approaches and has some specific implications.
In Agile:
- We do not view a piece of code as a solution. We need to think about the whole environment and deliver code that supports recognised needs of users, organisations and stakeholders
- A solution includes automated testing, maintainability, resusability and other things. We think about these and include them in the development from day 1. We do not 'add it on' afterwards
- We think from initial idea to deployed and working (and maintained/improved) solution, involving relevant people at all stages. However, we do not try to think beyond the available information. This means we plan in just sufficient detail and just-in-time. The plan is an evolving part of the ongoing project
- To facilitate flexibility and maintainability of our systems we use standards-based approaches where possible and choose architectures which allow us to defer and easily modify details of our implementations
- We start with an understanding of what we are trying to achieve, but we recognise that what is possible and sensible may evolve as our understanding of the problem and context changes. We use short development cycles and close interaction with users and stakeholders to ensure we deliver the best solution within the constraints